Video Activity Recognition Exercise: CNN + LSTM
(NOTE: alternative with image captioning rather than video activity recogntion https://www.freecodecamp.org/news/building-an-image-caption-generator-with-deep-learning-in-tensorflow-a142722e9b1f/)
- Using Keras (which can sit on top of Tensorflow) https://www.pyimagesearch.com/2019/07/15/video-classification-with-keras-and-deep-learning/
- Overview and problem computation (so many paramerers = LONG training times, run out of memory --see below too and why method 4 works best ) http://blog.qure.ai/notes/deep-learning-for-videos-action-recognition-review
DO MEthod 4 (because other options can run out of memory and too long to train) of https://blog.coast.ai/five-video-classification-methods-implemented-in-keras-and-tensorflow-99cad29cc0b5
Method #4: Extract features with a CNN, pass the sequence to a separate RNN
Given how well Inception did at classifying our images, why don’t we try to leverage that learning? In this method, we’ll use the Inception network to extract features from our videos, and then pass those to a separate RNN.
This takes a few steps.
First, we run every frame from every video through Inception, saving the output from the final pool layer of the network. So we effectively chop off the top classification part of the network so that we end up with a 2,048-d vector of features that we can pass to our RNN. For more info on this strategy, see my previous blog post on continuous video classification.
Second, we convert those extracted features into sequences of extracted features. If you recall from our constraints, we want to turn each video into a 40-frame sequence. So we stitch the sampled 40 frames together, save that to disk, and now we’re ready to train different RNN models without needing to continuously pass our images through the CNN every time we read the same sample or train a new network architecture.
For the RNN, we use a single, 4096-wide LSTM layer, followed by a 1024 Dense layer, with some dropout in between. This relatively shallow network outperformed all variants where I tried multiple stacked LSTMs. Let’s take a look at the results:

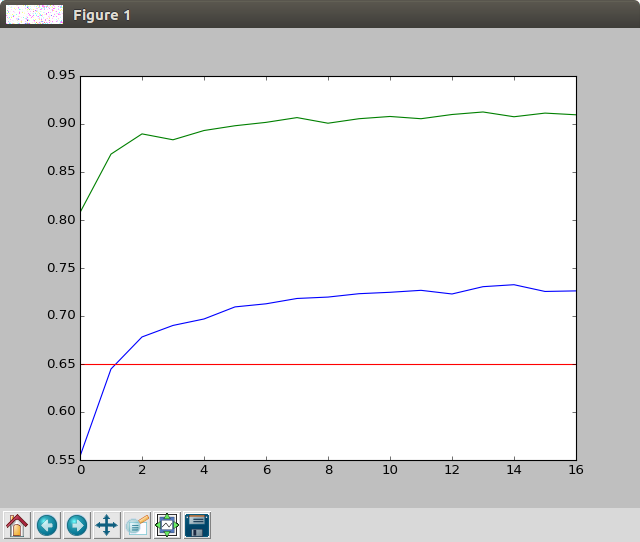
Hey that’s pretty good! Our first temporally-aware network that achieves better than CNN-only results. And it does so by a significant margin.
Final test accuracy: 74% top 1, 91% top 5