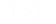Some Factors Influencing Training: Batch Size, Learning Rate
Batch Size
Batch size is the number of examples from the training dataset used in the estimation of the error gradient for an update of the model weights. This is an important hyperparameter that influences the dynamics of the learning algorithm. For example, A batch size of 32 means that 32 samples from the training dataset will be used to estimate the error gradient before the model weights are updated.
-
Batch Gradient Descent . Batch size is set to the total number of examples in the training dataset.
-
Stochastic Gradient Descent . Batch size is set to one.
-
Minibatch Gradient Descent . Batch size is set to more than one and less than the total number of examples in the training dataset.
In the below graph we will see the effect of batch size on training/testing accuracy and loss
64 batch size 256 batch size 1024 batch size
For this dataset all the tried batch sizes work however smaller than 64 this would possibly yield too much variation and make learning unstable.
-
●Too large of a batch size will lead to poor generalization
●Using a batch equal to the entire dataset guarantees convergence to the global optima.
●Using smaller batch sizes leads faster convergence to “good” solutions.
●Smaller batch sizes allow the model to “start learning before having to see all the data.”
●The downside of using a smaller batch size is that the model is not guaranteed to converge to the global optima.
●Smaller batch sizes make it easier to fit one batch worth of training data in memory (i.e. when using a GPU).
Learning Rate
The hyperparameter learning rate is the factor by which the weights are updated at each epoch. Selecting the right learning rate for gradient descent is important to ensure that the algorithm converges at an optimal solution.
-
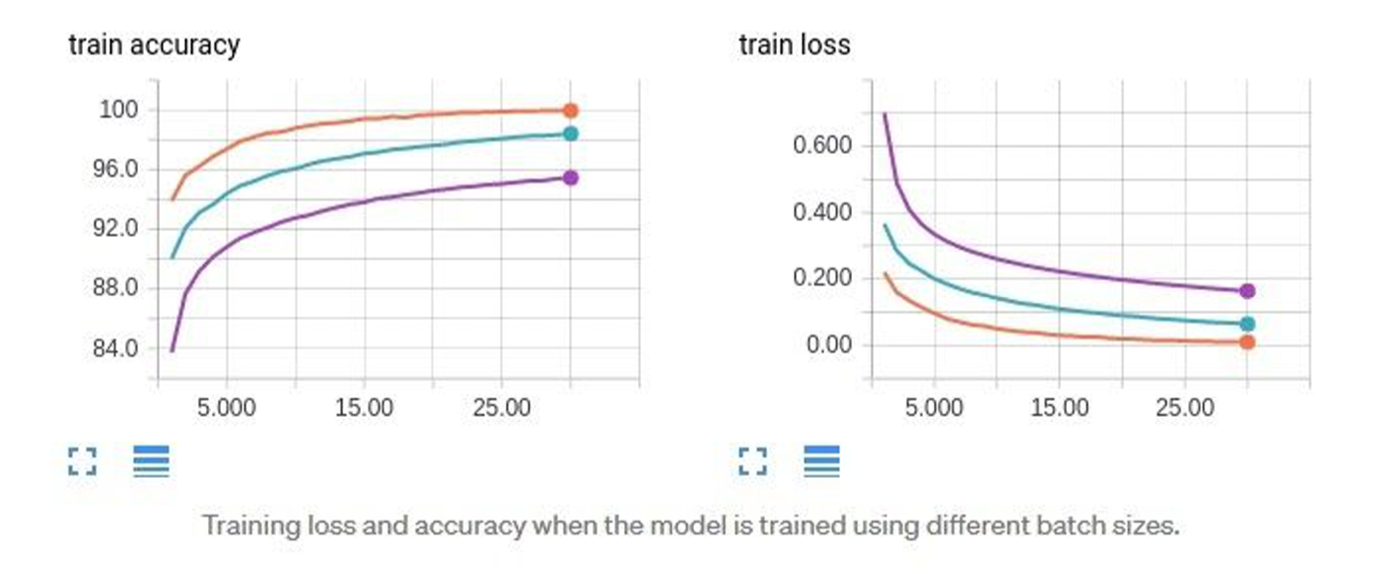
too large a learning rate poses the risk of exploding gradients and the algorithm may never converge.
a small learning rate can ensure that gradient descent converges, it can also slow down the learning as the algorithm makes little progress with each epoch and can take longer to converge.
BEST PRACTICE: Use experience (or look to others published work) for learning rates used. If the rate is too large, reduce it. If time allows do "parameter tunning" where you try a number of learning rates.
The learning rate -- a bigger value means you change more dramatically the weights/ values of your network --its more quickly changing (higher learning rate) ---but, wutg small batch sizes you want smaller learning rates (as with smaller number of samples used in batch means you are less certain of the error being reprntative of the entire data). See the result of different learning rates when too high and "just right" to lower.
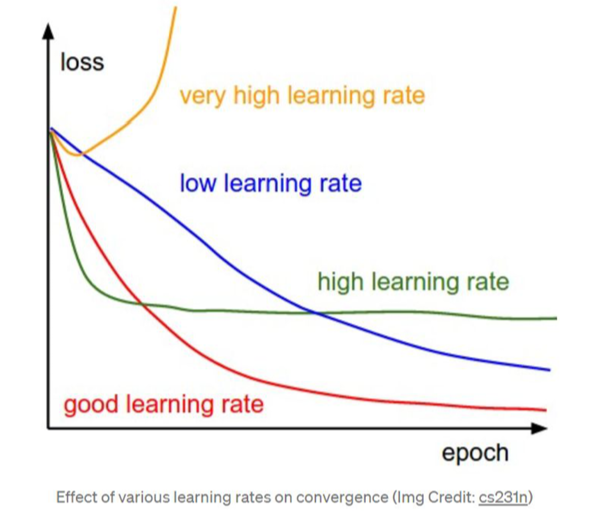
Learning Rate Functions (vary over training)
There are all kinds of ways to alter the learning rate over time and this is what typically tensorflow (or other frameworks) do. There are step learning rates --where at specific # of steps you change the learning rate --you might start higher then decrease it over time (you might start higher to allow you to jump around more quickly in your optimization space --or rather your mulit-dimensional space of all weights --each a different dimension) . So "step decay" is one possibility. Another is cosine decay --it starts "larger" then decays more gradually. There is also "exponential decay functions". So as you can see there are options. Below is the related info from our current detection config file
optimizer {
momentum_optimizer:
{ learning_rate:
{ cosine_decay_learning_rate
{ learning_rate_base: 8e-2 total_steps: 300000
warmup_learning_rate: .001
warmup_steps: 2500
}
}
what is this? It means we are using a coside_decay_lear_rate function. I do NOT know exactly how the Object Detection API turns these into the exact shape of the cosine function that alters the learning rate over training steps. Look at this
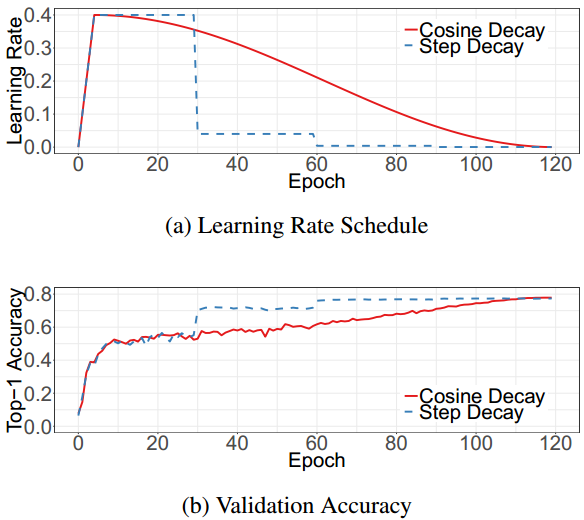
the top shows you how a step decay just drops it over time where cosine is a smooth chage
Now the exact shape of the cose decay is a function of the numbers in the config file ---exactly what they mean in this new TF2 Object Detection API --don't know ---they have no decent documentation. Here is the documentation for TF2 Keras https://www.tensorflow.org/api_docs/python/tf/keras/experimental/CosineDecay
TIP on SELECTING LEARNING RATE & FUNCTION
-
If you are running very small batch size - You need to lower the warmup learning rate (that is the inital rate that is higher before the cosine) and probably also the learning_rate_base ---how much not sure...we can do trial or error or look for some real documentation. Do you understand better
-
Each network and each dataset will be different and can work well with different learning rates. this is one of the HARD (who knows the best value without trying lots of them) value----what I and others do is use experience or other peoples on similar data sets/models where they have a set learning rate and start there.
-
If your data is wildly facilating and loss is not (yes there will be some fluctuation) going down to some point steadily (the final loss metric will depend on data, ammount, network architecure and basically everything)---then you should try lowering your learning rate and/or increasing batch size.
-
Why not always increase batch size --, ofcourse just storing in memory and performance as you see is an issue.
look at https://medium.com/@scorrea92/cosine-learning-rate-decay-e8b50aa455b#:~:text=The%20warm%2Dup%20consists%20of,decay%20using%20the%20cosine%20function

TIP: IF YOU ARE SEEING YOUR LOSS rising to infinity:
-
NOW this idea of going to inifity in loss --there is a real problem there ---open possibility is divergence from a TOO large learning rate ..https://stackoverflow.com/questions/40050397/deep-learning-nan-loss-reasons
-
LOWER LEARNING RATE (how much?): Drop it by 1 to 3 orders of magnitude meaning multiple number by 0.1 to 0.001 to see if a lower learning rate will help