Memcached
memcached is a general-purpose distributed memory caching system that is used by some websites. It is used to speed up dynamic database-driven websites by caching data and objects in memory to reduce the amount the database needs to be read. Memcached is distributed under a permissive free software licence.[1]
- lacks authentication and security features
- use only behind a firewall
- default port 11211
- uses libevent.
- API provides a mechanism to execute a callback function when a specific event occurs on a file descriptor or after a timeout has been reached. also support callbacks due to signals or regular timeouts.
- meant to replace the event loop found in event-driven network servers. An application just needs to call event_dispatch() and then add or remove events dynamically without having to change the event loop.
- Using callbacks on signals, libevent makes it easy to write secure signal handlers as none of the user supplied signal handling code runs in the signal's context.
- Used by several very large, well-known sites including YouTube, LiveJournal, Slashdot, Wikipedia, SourceForge, GameFAQs, Facebook, Digg, Fotolog, etc.
THE IDEA
|
||
Implementation
|
||
Example Pseudo-Code
|
||
More Pseudo-Codeyou need to make sure that when you make calls to update the database you also, update your cache.
What else do you need? Removal and Insertion operations so that the database and cache are consistent.....could use this update_data function where for removal dbUpdateString is null and for insertion, simply the value. |
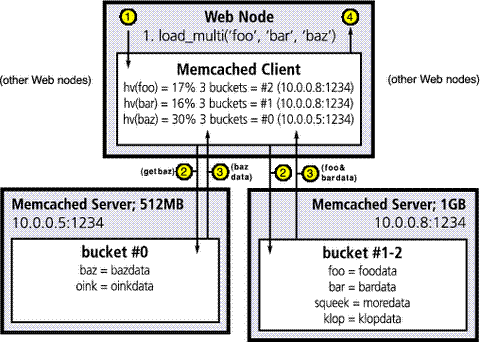
How It Works: retrieval of information.....a request for keys foo, bar, baz
Step 1: the application requests keys foo, bar and baz using the client library, which calculates key hash values, determining which Memcached server should receive requests. Step 2: the Memcached client sends parallel requests to all relevant Memcached servers. Step 3: the Memcached servers send responses to the client library. Step 4: the Memcached client library aggregates responses for the application. If some or all of the requests failed to find results...then a database call must be made next. |
An Example, LiveJournal.comyear 200X: from http://www.linuxjournal.com/article/7451 LiveJournal.com has 28 Memcached instances running on our network on ten unique hosts, caching the most popular 30GB of data. Our hit rate is around 92%, which means we're hitting our databases a lot less often than before. On our Web nodes with 4GB of memory, we run three Memcached instances of 1GB each, then mod_perl using 500MB, leaving 500MB of breathing room. Running Memcached on the same machine as mod_perl works well, because our mod_perl code is CPU-heavy, whereas Memcached hardly touches the CPU. Certainly, we could buy machines dedicated to Memcached, but we find it more economical to throw up Memcached instances wherever we happen to have extra memory and buy extra memory for any old machine that can take it. You even can run a Memcached farm with all instances being different sizes. We run a mix of 512MB, 1GB and 2GB instances. You can specify the instances and their sizes in the client configuration, and the Memcached connection object weights appropriately. Speed
Of course, the primary motivation for caching is speed, so Memcached is designed to be as fast as possible. The initial prototype of Memcached was written in Perl. Although I love Perl, the prototype was laughably slow and bloated. Perl trades off memory usage for everything, so a lot of precious memory was wasted, and Perl can't handle tons of network connections at once. The current version is written in C as a single-process, single-threaded, asynchronous I/O, event-based dæmon. For portability and speed, we use libevent (see the on-line Resources section) for event notification. The advantage of libevent is that it picks the best available strategy for dealing with file descriptors at runtime. For example, it chooses kqueue on BSD and epoll on Linux 2.6, which are efficient when dealing with thousands of concurrent connections. On other systems, libevent falls back to the traditional poll and select methods. Inside Memcached, all algorithms are O(1). That is, the runtime of the algorithms and CPU used never varies with the number of concurrent clients, at least when using kqueue or epoll, or with the size of the data or any other factor. Of note, Memcached uses a slab allocator for memory allocation. Early versions of Memcached used the malloc from glibc and ended up falling on their faces after about a week, eating up a lot of CPU space due to address space fragmentation. A slab allocator allocates only large chunks of memory, slicing them up into little chunks for particular classes of items, then maintaining freelists for each class whenever an object is freed. See the Bonwick paper in Resources for more details. Memcached currently generates slab classes for all power-of-two sizes from 64 bytes to 1MB, and it allocates an object of the smallest size that can hold a submitted item. As a result of using a slab allocator, we can guarantee performance over any length of time. Indeed, we've had production Memcached servers up for 4–5 months at a time, averaging 7,000 queries/second, without problems and maintaining consistently low CPU usage.
|
other exampleshttp://highscalability.com/flickr-architecture http://highscalability.com/scaling-twitter-making-twitter-10000-percent-faster |
Memcached Apis |