Encoding (and language)
-
Encoding can mean different things in computer science depending on the application.
-
When discussing Internationalization, encoding is the specification of the standard you are using to save your document/file in terms of text code.
Have you ever noticed the meta tag in the header of an HTML file:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"
This indicates you are encoding with the charset encoding standard called UTF-8
Encoding Standards
-
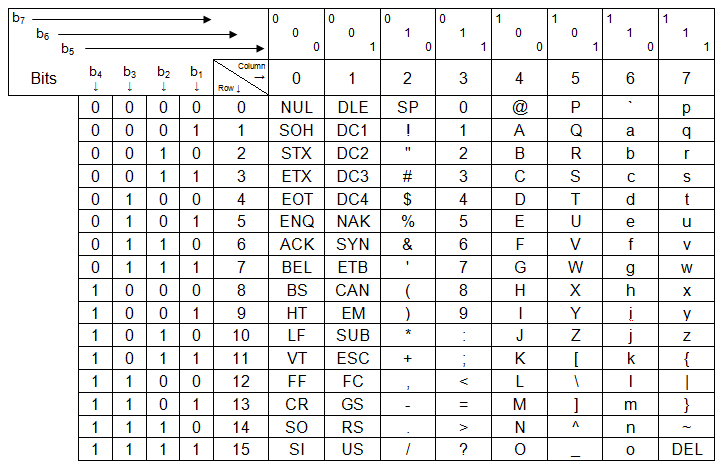
ASCII - this is a standard that was developed a long time ago
-
7 bits per character
-
stands for American Standard Code for Information Interchange
-
not enough bits to represent some language's characters (japanese, chinese)
-
-
UNICODE - (www.unicode.org)
-
Developed to represent extended character set needed for other languages.
-
ASCII was incorporated into the Unicode character set as the first 128 symbols, so the ASCII characters have the same numeric codes in both sets. This allows UTF-8 to be backward compatible with ASCII, a significant advantage.
-
more than 109,000 characters covering 93 scripts.
-
Multipel versions of Unicode
-
Multiple standards are part of Unicode
-
UFT-8 , UTF-16, and more
-
UTF-8: (a variable bit length character representation scheme)
-
uses 1 byte for any ASCII characters, which have the same code values in both UTF-8 and ASCII encoding,
-
-
AND to 4 bytes for other characters.
-
most popular?
-
UTF-16: (fixed bit length character representation scheme)
-
uses 2 bytes for most characters.
-
uses 4 bytes to handle remaining characters.
-
-
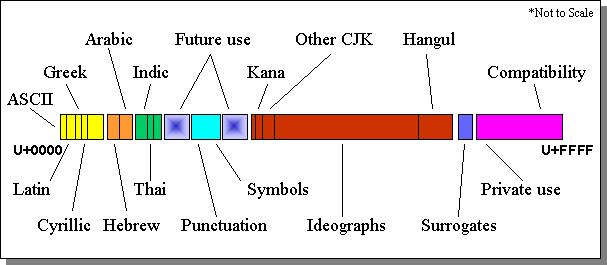
Unicode Plane "0" represents most of the western and other common languages
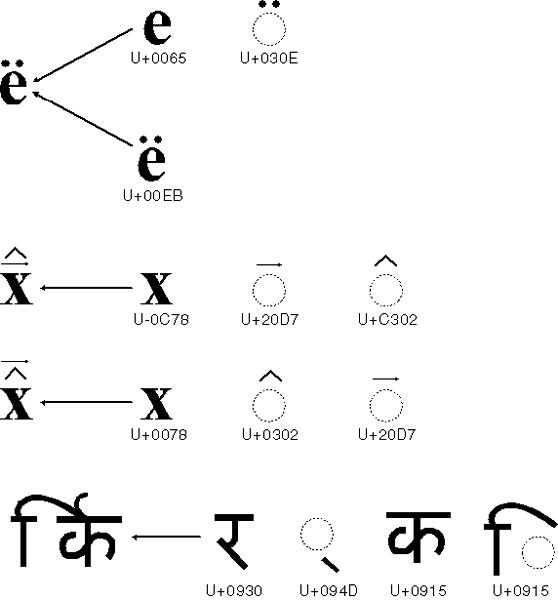
UNICODE: shows how some characters in languages are made up of multiple base symbols. Some languages are comprised of symbol composition.
What do you do?
Instructor Recommendation: Always use a Unicode standard when possible to save your documents. If you are using a tool that lets you save in different character encoding schemes like dreamweaver for html documents --make sure that you choose a Unicode standard.
Operating Systems and Files
-
Unicode has become the dominant scheme for internal processing and storage of text
-
UTF-16: Windows Operating Systems (starting at NT to current versions), Mac OS
- NOTE: Operating systems must have ability to support different standards although will typically have a defauls. For example in Windows ---All Win32 APIs that take a text argument either as an input or output variable have been provided with a generic function prototype and two definitions: a version that is based on code pages or ANSI (called "A") to handle code page-based text argument and a wide version (called "W ") to handle Unicode.
- Example Windows C programming -- has strcpy for copying of ASCII 8 bit strings AND has wcspy for copying of UNICODE strings.
- UTF-8 : Unix operating sytems typically use this standard. (see your version of Unix's documentation)
Java and .NET
The Java and .NET bytecode environments use UTF-16
- Look up specifics of each platform (and in the case of .NET the language) to understand what support is given for UNICODE.
- Example in .NET for C programming have mbtowc and wctomb, which can translate the C character set to and from Unicode
.NET tips ---from Microsoft
- Unicode UTF-16 encoding. Use the UnicodeEncoding class to convert characters to and from UTF-16 encoding.
- Unicode UTF-8 encoding. Use the UTF8Encoding class to convert characters to and from UTF-8 encoding.
ASP .NET example -- setting encoding to UTF-8
To determine the encoding to use for response characters in an Active Server Pages for the .NET Framework (ASP.NET) application, set the value of the HttpResponse.ContentEncoding property to the value returned by the appropriate method. The following code example illustrates how to set HttpResponse.ContentEncoding.
// Explicitly set the encoding to UTF-8.
Response.ContentEncoding = Encoding.UTF8;// Set ContentEncoding using the name of an encoding.
Response.ContentEncoding = Encoding.GetEncoding(name);// Set ContentEncoding using a code page number.
Response.ContentEncoding = Encoding.GetEncoding(codepageNumber);
Microsoft C tips ---from Microsoft
- Modify your code to use generic data types. Determine which variables declared as char or char* are text, and not pointers to buffers or binary byte arrays. Change these types to TCHAR and TCHAR*, as defined in the Win32 file WINDOWS.H, or to _TCHAR as defined in the Visual C++ file TCHAR.H. Replace instances of LPSTR and LPCH with LPTSTR and LPTCH. Make sure to check all local variables and return types. Using generic data types is a good transition strategy because you can compile both ANSI and Unicode versions of your program without sacrificing the readability of the code. Don't use generic data types, however, for data that will always be Unicode or always stays in a given code page. For example, one of the string parameters to MultiByteToWideChar and WideCharToMultiByte should always be a code page-based data type, and the other should always be a Unicode data type.
- Modify your code to use generic function prototypes. For example, use the C run-time call _tcslen instead of strlen, and use the Win32 API SetWindowText instead of SetWindowTextA. This rule applies to all APIs and C functions that handle text arguments.
- Surround any character or string literal with the TEXT macro. The TEXT macro conditionally places an "L" in front of a character literal or a string literal definition. Be careful with escape sequences. For example, the Win32 resource compiler interprets L/" as an escape sequence specifying a 16-bit Unicode double-quote character, not as the beginning of a Unicode string.
- Create generic versions of your data structures. Type definitions for string or character fields in structures should resolve correctly based on the UNICODE compile-time flag. If you write your own string-handling and character-handling functions, or functions that take strings as parameters, create Unicode versions of them and define generic prototypes for them.
- Change your build process. When you want to build a Unicode version of your application, both the Win32 compile-time flag -DUNICODE and the C run-time compile-time flag -D_UNICODE must be defined.
- Adjust pointer arithmetic. Subtracting char* values yields an answer in terms of bytes; subtracting wchar_t* values yields an answer in terms of 16-bit chunks. When determining the number of bytes (for example, when allocating memory for a string), multiply the length of the string in symbols by sizeof(TCHAR). When determining the number of characters from the number of bytes, divide by sizeof(TCHAR). You can also create macros for these two operations, if you prefer. C makes sure that the ++ and -- operators increment and decrement by the size of the data type. Or even better, use Win32 APIs CharNext and CharPrev.
- Check for any code that assumes a character is always 1 byte long. Code that assumes a character's value is always less than 256 (for example, code that uses a character value as an index into a table of size 256) must be changed. Make sure your definition of NULL is 16 bits long.
- Add code to support special Unicode characters. These include Unicode characters in the compatibility zone, characters in the Private Use Area, combining characters, and characters with directionality. Other special characters include the Private Use Area noncharacter U+FFFF, which can be used as a placeholder, and the byte-order marks U+FEFF and U+FFFE, which can serve as flags that indicate a file is stored in Unicode. The byte-order marks are used to indicate whether a text stream is little-endian or big-endian. In plaintext, the line separator U+2028 marks an unconditional end of line. Inserting a paragraph separator, U+2029, between paragraphs makes it easier to lay out text at different line widths.
- Debug your port by enabling your compiler's type-checking. Do this with and without the UNICODE flag defined. Some warnings that you might be able to ignore in the code page-based world will cause problems with Unicode. If your original code compiles cleanly with type-checking turned on, it will be easier to port. The warnings will help you make sure that you are not passing the wrong data type to code that expects wide-character data types. Use the Win32 National Language Support API (NLS API) or equivalent C run-time calls to get character typing and sorting information. Don't try to write your own logic for handling locale-specific type checking-your application will end up carrying very large tables!
EXAMPLE - take some C code using ASCII strings and convert to generic
BEFORE
char g_szTemp[MAX_STR]; // Using the loaded string in a call to TextOut //for drawing at run time |
AFTER #include TCHAR g_szTemp[MAX_STR];
After implementing these simple steps, all that is left to do in order to create a Unicode application is to compile your code as Unicode by defining the compiling flags UNICODE and _UNICODE. |
CGI Programs --taking in user input from browser
- Internally, a CGI program (and the system it is running in) may communicate all with Unicode strings if you set this up.
- Web pages may consist of content that can be in Windows or other character-encoding schemes besides Unicode. Therefore, when form or query-string values come in from the browser in an HTTP request, they must be converted from the character set used by the browser into Unicode for processing by the Unicode based CGI program.
- Your CGI program must do any necessary language based selections or translations to work ---maybe you have a different database for "es-MX" mexico than for "en-US" united states.
HTML and CSS
UTF-8 is also the most common Unicode encoding used in HTML documents and other text documents on the WWW.
Unicode Spcification
- You can specify in header the Encoding scheme
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=<value>">
Language Specification (entire document)
- You can specify in the header the language of the content of the page you are delivering to a client ---for example for english
<meta http-equiv="content-language" content="en" />
for spanish
<meta http-equiv="content-language" content="es" /> 2 DIGIT Language Specification
AA "Afar"
AB "Abkhazian"
AF "Afrikaans"
AM "Amharic"
AR "Arabic"
AS "Assamese"
AY "Aymara"
AZ "Azerbaijani"
BA "Bashkir"
BE "Byelorussian"
BG "Bulgarian"
BH "Bihari"
BI "Bislama"
BN "Bengali" "Bangla"
BO "Tibetan"
BR "Breton"
CA "Catalan"
CO "Corsican"
CS "Czech"
CY "Welsh"
DA "Danish"
DE "German"
DZ "Bhutani"
EL "Greek"
EN "English" "American"
EO "Esperanto"
ES "Spanish"
ET "Estonian"
EU "Basque"
FA "Persian"
FI "Finnish"
FJ "Fiji"
FO "Faeroese"
FR "French"
FY "Frisian"
GA "Irish"
GD "Gaelic" "Scots Gaelic"
GL "Galician"
GN "Guarani"
GU "Gujarati"
HA "Hausa"
HI "Hindi"
HR "Croatian"
HU "Hungarian"
HY "Armenian"
IA "Interlingua"IE "Interlingue"
IK "Inupiak"
IN "Indonesian"
IS "Icelandic"
IT "Italian"
IW "Hebrew"
JA "Japanese"
JI "Yiddish"
JW "Javanese"
KA "Georgian"
KK "Kazakh"
KL "Greenlandic"
KM "Cambodian"
KN "Kannada"
KO "Korean"
KS "Kashmiri"
KU "Kurdish"
KY "Kirghiz"
LA "Latin"
LN "Lingala"
LO "Laothian"
LT "Lithuanian"
LV "Latvian" "Lettish"
MG "Malagasy"
MI "Maori"
MK "Macedonian"
ML "Malayalam"
MN "Mongolian"
MO "Moldavian"
MR "Marathi"
MS "Malay"
MT "Maltese"
MY "Burmese"
NA "Nauru"
NE "Nepali"
NL "Dutch"
NO "Norwegian"
OC "Occitan"
OM "Oromo" "Afan"
OR "Oriya"
PA "Punjabi"
PL "Polish"
PS "Pashto" "Pushto"
PT "Portuguese"
QU "Quechua"RM "Rhaeto-Romance"
RN "Kirundi"
RO "Romanian"
RU "Russian"
RW "Kinyarwanda"
SA "Sanskrit"
SD "Sindhi"
SG "Sangro"
SH "Serbo-Croatian"
SI "Singhalese"
SK "Slovak"
SL "Slovenian"
SM "Samoan"
SN "Shona"
SO "Somali"
SQ "Albanian"
SR "Serbian"
SS "Siswati"
ST "Sesotho"
SU "Sudanese"
SV "Swedish"
SW "Swahili"
TA "Tamil"
TE "Tegulu"
TG "Tajik"
TH "Thai"
TI "Tigrinya"
TK "Turkmen"
TL "Tagalog"
TN "Setswana"
TO "Tonga"
TR "Turkish"
TS "Tsonga"
TT "Tatar"
TW "Twi"
UK "Ukrainian"
UR "Urdu"
UZ "Uzbek"
VI "Vietnamese"
VO "Volapuk"
WO "Wolof"
XH "Xhosa"
YO "Yoruba"
ZH "Chinese"
ZU "Zulu"
Language Specification (HTML Elements) using lang attribute
- You can use lang attribute of some HTML elements to indicate language
- Example 1
<BODY LANG=fr>
- Example 2
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<HTML lang="fr">
<HEAD> <TITLE>Un document multilingue</TITLE> </HEAD>
<BODY> ...Interpreted as French...
<P lang="es">...Interpreted as Spanish...
<P>...Interpreted as French again...
<P>...French text interrupted by
<EM lang="ja">some Japanese</EM>French begins here again...
</BODY>
</HTML>
Direction of text (left to right and right to left)
- Use dir attribute for html tags (like body).
- dir = LTR | RTL [CI]
- This attribute specifies the base direction of directionally neutral text (i.e., text that doesn't have inherent directionality as defined in [UNICODE]) in an element's content and attribute values. It also specifies the directionality of tables. Possible values:
- LTR: Left-to-right text or table.
- RTL: Right-to-left text or table.
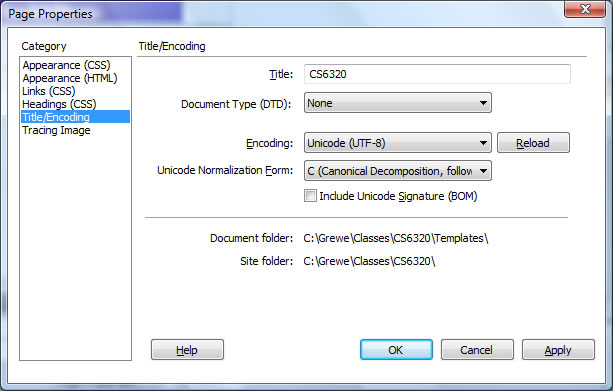
Example Options in DREAMWEAVERfor Encoding
1) Bring up "Page Properties" (on this page I am editing right now) and will get the following
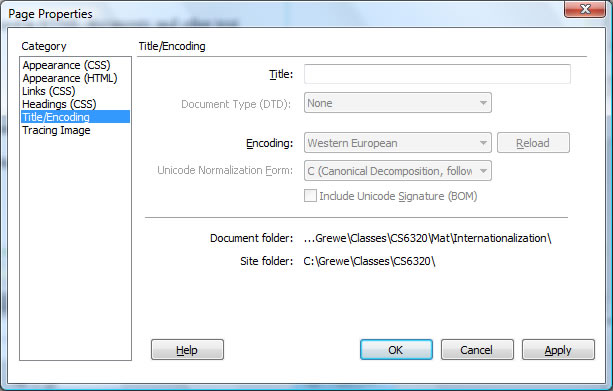
2) When I view "page properties" on the template from which this page is derived I get the following options for encoding where I can set the UTF standard