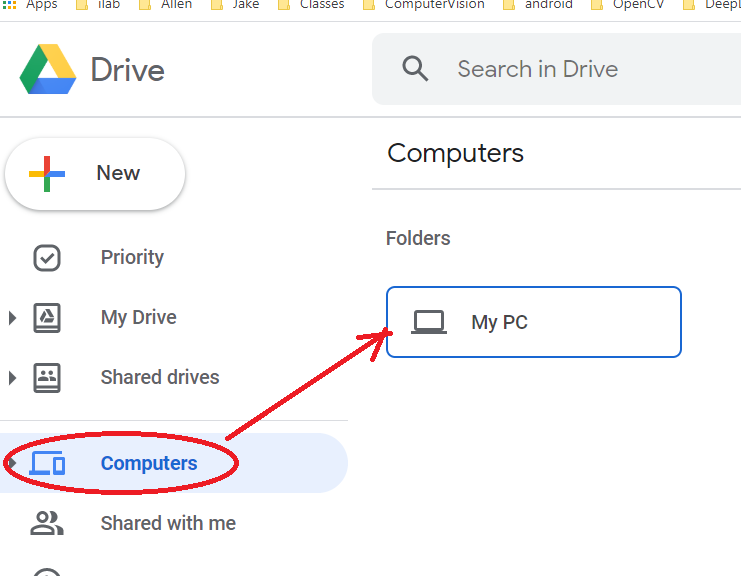
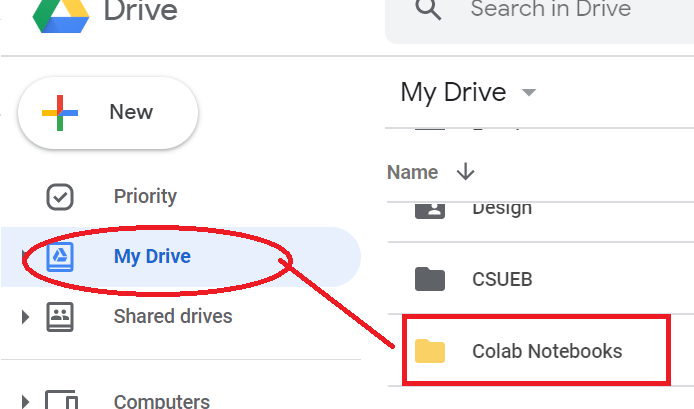
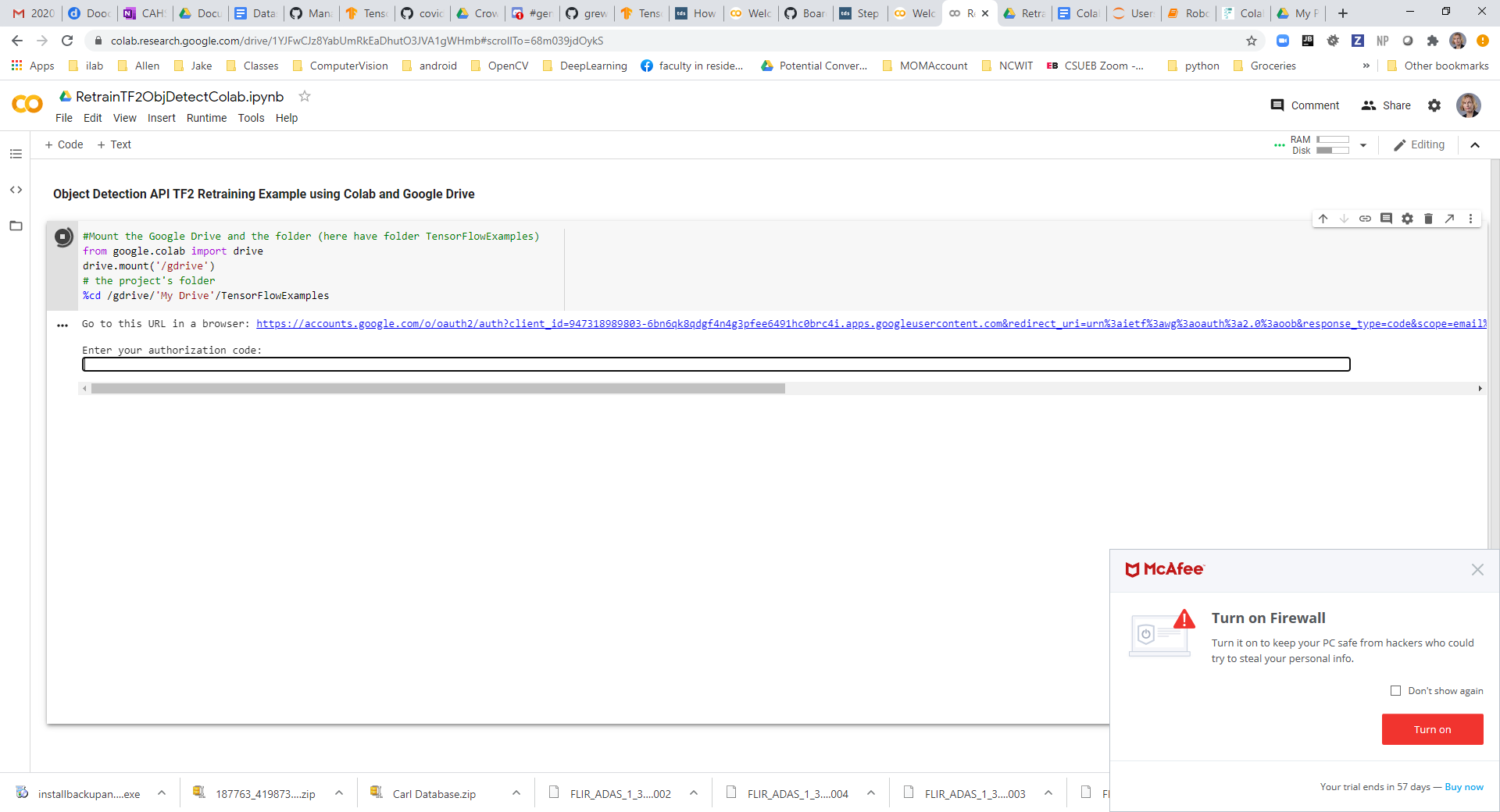
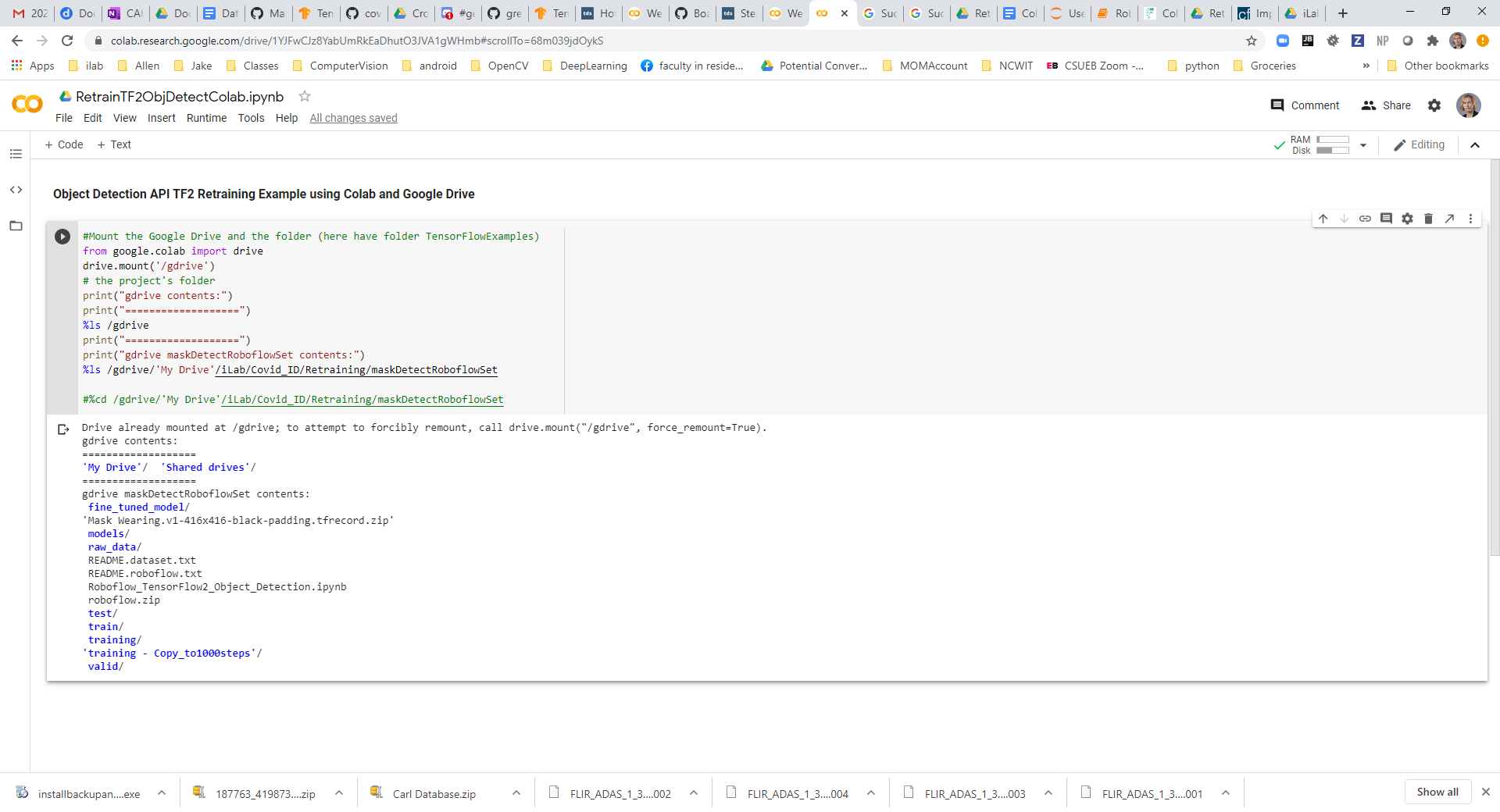
#adjusted from: https://github.com/datitran/raccoon_dataset
# converts the csv files for training and testing data to two TFRecords files. # places the output in the same directory as the input # NOTE: WEIRD PROBLEM with the paths for Mounted Google Drive here where need /gdrive/'My Drive'/*** to do any ls or cat # but to open a file for reading or writing need just /gdrive/My Drive/*** #QUESTION: why did the writing of the csv and pbtext work in cell up above with the 'My Drive' around path???????????
from object_detection.utils import dataset_util %cd {data_dir}
# problem with the data_dir not evaluating the 'My Drive' into My Drive #DATA_BASE_PATH = data_dir + '/' #image_dir = data_dir +'/images/' DATA_BASE_PATH = "/gdrive/My Drive/iLab/Covid_ID/Retraining/DetectionWeaponsExample/data/" images_dir = "/gdrive/My Drive/iLab/Covid_ID/Retraining/DetectionWeaponsExample/data/images/" print("Data base path " + DATA_BASE_PATH)
print("Images path " + images_dir)
#do a list to see if the record file already exists #this will falue when no 'My Drive' and using only My Drive #%ls {DATA_BASE_PATH}
#FIX- THIS IS HARDCODED method for converting the class label to its id instead!!! def class_text_to_int(row_label): if row_label == 'pistol': return 1 else: None
#some kind of parsing function that create a special DataSet for parsing each image in a loop def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
#This is a function that reads in image from a file (using tf.io package) and its bounding box information and creates # and instance of tf.train.Example that can be used to add to a TFRecord def create_tf_example(group, path): with tf.io.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() #open up io stream to file containing image encoded_jpg_io = io.BytesIO(encoded_jpg) #open up Image file pointer using the stream previously opened image = Image.open(encoded_jpg_io) #retrieve size of image from the data in the Image file pointer (stored in the jpg file) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' #setup array to represent all the bounding boxes for this image # bounding box i upper left point = (xmins[i],ymins[i]) lower right point =(xmaxs[i], ymaxs[i]) # class label of ith' box stored in classes_text[i] # also as building out this array add to classes[] any unique new classes found xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = []
#cycle through the rows in the label csv file pased and add in the bounding box info into arrays # and corresponding class label. for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class']))
#build out a tf.train.Example using all the read in information for this image and its bounding boxes # this will be used later to create a TFRecord # see https://www.tensorflow.org/tutorials/load_data/tfrecord for information about tf.train.Example and TFRecord format # as you can see includes for each image: # height, width, filename, the actual image pixel values, image format, # and bounding boxes (as arrays of xmin,ymin and xmax,ymax representing the lower-left and upper-right points) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example
#go through the train_labels.csv and afterwards test_lables.csv and create TFRecord files for each # pd is associated with loaded python Pandas module imported and used to read csv files for csv in ['train_labels', 'test_labels']: #use TFrecordWriter to write records to a TFRecord file as specified in path #see https://www.tensorflow.org/api_docs/python/tf/io/TFRecordWriter label_file = DATA_BASE_PATH + csv + '.record' print(".........going to save TFRecord to " + label_file) # label_file = "/" writer = tf.io.TFRecordWriter(DATA_BASE_PATH + csv + '.record') #writer = tf.io.TFRecordWriter(dummy2) path = os.path.join(images_dir)
#read in all the rows in the csv file using pandas module into a pandas DataFrame datastructure #see https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html #see https://pandas.pydata.org/pandas-docs/stable/reference/frame.html # need file to open = "/gdrive/My Drive/iLab/Covid_ID/Retraining/DetectionWeaponsExample/data/" + csv + ".csv" print(DATA_BASE_PATH + csv + '.csv') examples = pd.read_csv(DATA_BASE_PATH + csv + '.csv')
#For each image group it with its bounding boxes grouped = split(examples, 'filename')
#for each image and its bounding boxes create an instance of tf.train.Example that is # written out into a file that is the created TFRecord file # see https://www.tensorflow.org/tutorials/load_data/tfrecord # for information about tf.train.Example and TFRecord format for group in grouped: print(" group in loop ") print(group) tf_example = create_tf_example(group, path) writer.write(tf_example.SerializeToString()) writer.close() output_path = os.path.join(os.getcwd(), DATA_BASE_PATH + csv + '.record') print('Successfully created the TFRecords: {}'.format(DATA_BASE_PATH +csv + '.record'))
|