Speech
Speech Recognition -
The goal is to understand speech utterances.
Many applications. This covers the application of many techniques
including HMMs (hidden markov models), neural-nets, statistical
pattern recognition.
Speaker Verification: is confirming the identity of an
individual from his speech.
|
Speech Synthesis -
The generation of artifical speech utterances. Typically used
in automated response systems. Also used in text to speech applications.
|
Speech Coding and Compression -
The representation and reduction of storage needed to save speech
samples.
|
Phonetics/Linguistics -
Area of study of speech in terms of sounds (phonetics) and other
language issues like syntax, etc. (inguistics) all of which are
used in the applications above. Could cover parsing, natural language
processing, phonology and prosodic work.
|
Steps in Speech Recognition
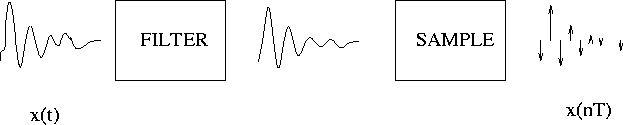
Sampling
This is where you sample, create a discrete number of sample
points for an analog speech signal being recorded from say a phone
or microphone or similar device.
minimum sampling (poor speech): For recorded speech to
be understood by humans you need an 8kHz sampling rate or more
and at least 8 bit sampling. Improvements can be achieved by increasing
the number of bits in sampling to 12bits or 16bits, or by using
a non-linear encoding technique such as mu-law or A-law. This
improves the "signal-to-noise" ratio.
typicall sampling (adequate for most speech recognition)
A 16kHz sampling rate is a reasonable target for high quality
speech recording and playback.
|
Endpoint detection is the detection of the start and stop of
speech utterances in a sound sample
Blocking/Windowing is the breaking up of speech utterances into
smaller windows of time (i.e. 10-30ms).
Accurate end-pointing is a non-trivial task, however, reasonable
behaviour can be obtained for inputs which contain only speech
surrounded by silence (no other noises).
Typical algorithms look at the energy or amplitude of the incoming
signal and at the rate of "zero-crossings". A zero-crossing is
where the audio signal changes from positive to negative or visa
versa. When the energy and zero-crossings are at certain levels,
it is reasonable to guess that there is speech. More detailed
descriptions are provided in the papers
|
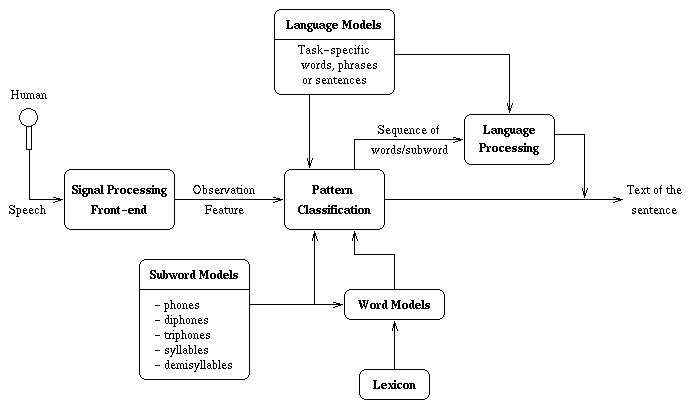
Signal Processing: Preprocessing, Feature Extraction and Postprocessing
Preprocessing
so far we have issolated a potential speech utterance but,
this does not mean the time sample we have is devoid of noise.
Plus there are other issues like speaker rate variation as well
as pitch changes between speakers that can influence the performance
of a recognition system. Many times speech signals are processed
not only in the temporal domain but, also in the frequency (spectral)
domain.
Feature Exatraction
Rather than processing the raw data samples, sometimes speech
systems try to extract higher-order information. This serves
2 purposes:
- reduction in the ammount of information to be processed
- hopefully more meaningful information is input into the
recognition system.
This stage can be optional. Feature extraction can take place
in either the spatial or spectral/frequence domain.
|
Temporal Feature Extraction
Extracting feqtures of speech from each frame in the
time domain has the advantage of simplicity, quick calculation,
and easy physical interpretation.
These temporal feature include:
- short-time avaerage energy and amplitude,
- short-time zero-crossing rate,
- short-time autocorrelation,
- pitch periods,
- root mean square (rms),
- maximum of amplitude, vocing quality,
- different between maximum and minmum values in
the positive and negative halves of the signal,
- autocorrelation peaks.
|
|
Spectral/Frequence Features
The features in the frequency domain may include:
- the difference between peak and valley,
- the energy in a particular frequency region,
- the spectral gradient
- spectral variation contour.
|

|
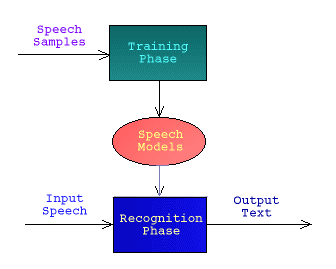
Some systems take advantage of having a training session with
a user that can tune the recognition algorithms used for better
performance. This is called Speaker-dependent Recognition (works
somewere at 98%-? accuracy)
Recognition without training is a more difficult problem and
is called Speaker-independent Recognition (works somewhere
around 95-?% accuracy).
There are many algorithms that have been developed for Recognition.
Most use statistical pattern recognition approaches, other may
also incorporate Natural Language Processing. Important issues
include speed and accurancy. In some sense, search and optimization
are part of the recognition process ("find the utterance
that matches with the minimum error").
|
|